
Hi, I am En Yu (于恩 in Chinese), a PhD student at Huazhong University of Science and Technology (HUST) and visting PhD at University of California, Santa Barbara (UCSB), cooperated with Prof.William Wang. I am currently interning at the Foundation Model Group of StepFun, where I work with Prof. Xiangyu Zhang and Dr. Zheng Ge.
My research interest includes (1) Perception, Understanding and Reasoning with Multimodal LLMs, and (2) Spatial Intelligence of Visual and Multimodal Foundation Models. I have published several papers at the top-level international AI conferences including ICLR, NeurIPS, CVPR, ECCV, ICCV, AAAI, ICML, etc. My next goal is to further build powerful multimodal foundation models and develop multimodal agents based on the foundation model to deal with complex real-world tasks, e.g., navigation, GUI-assistant and robotic tasks.
🎺🎺 I’ am set to graduate with my Ph.D. in June 2026 and am currently on the lookout for postdoctoral positions. If you are interested, please feel free to reach out to me via email !
🔥 News
-
2026.01: 🔥🔥 We present Step-VL-10B, the best 10B multimodal model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. All weights are open, check them out!🚀🚀
-
2025.09: 🎉🎉 Happy to share that our paper Perception-R1 and OVR have both been accepted at NeurIPS 2025! Have fun in San Diego!
-
2025.04: 🎉🎉 We present Perception-R1. This work takes a pioneering step in exploring the potential of rule-based RL in MLLM post-training for perception policy learning.
-
2025.02: 🎉🎉 Glad to announce that we have two papers, Video-UTR and OVTR, accepted for poster presentations at ICLR 2025! Let’s see and have a chat in Singapore!
-
2024.11: 🎉🎉 We present OVTR, the first fully end-to-end open-vocabulary multiple objects tracking framework.
-
2024.11: 🎉🎉 We present Video-UTR, investigating the shortcut learning in video multimodal large language models and systemally establish temporal hacking theory.
-
2024.07: 🎉🎉 Really excited to head to UCSB for a year-long PhD visiting in Prof. William Wang’s NLP lab. Looking forward to boosting my research ability. Catch you all in California!
-
2024.06: 🍾🍺 Excited to share that our work, Merlin, has been accepted as a poster presentation at ECCV 2024! See you in Milan!
-
2024.02: 🎉🎉 Glad to announce that our work, ChatSpot, has been accepted for a Long Oral presentation at IJCAI 2024! See you in Jeju!
-
2023.12: 🎉🎉 We present Merlin, the first end-to-end multimodal large language model that supports video-level visual localization (including tracking, video recognition, video registration, etc.) and future reasoning.
-
2023.07: 🎉🎉 We present ChatSpot, a unified end-to-end multimodal large language model that supports diverse forms of interactivity including mouse clicks, drag-and-drop, and drawing boxes, which provides a more flexible and seamless interactive experience.
-
2023.05: 🎉🎉 We present MOTRv3, a fully end-to-end multiple object tracking model that achieves SOTA performance on DanceTrack, which outperforms the tracking-by-detection trackers for the first time.
📝 Publications
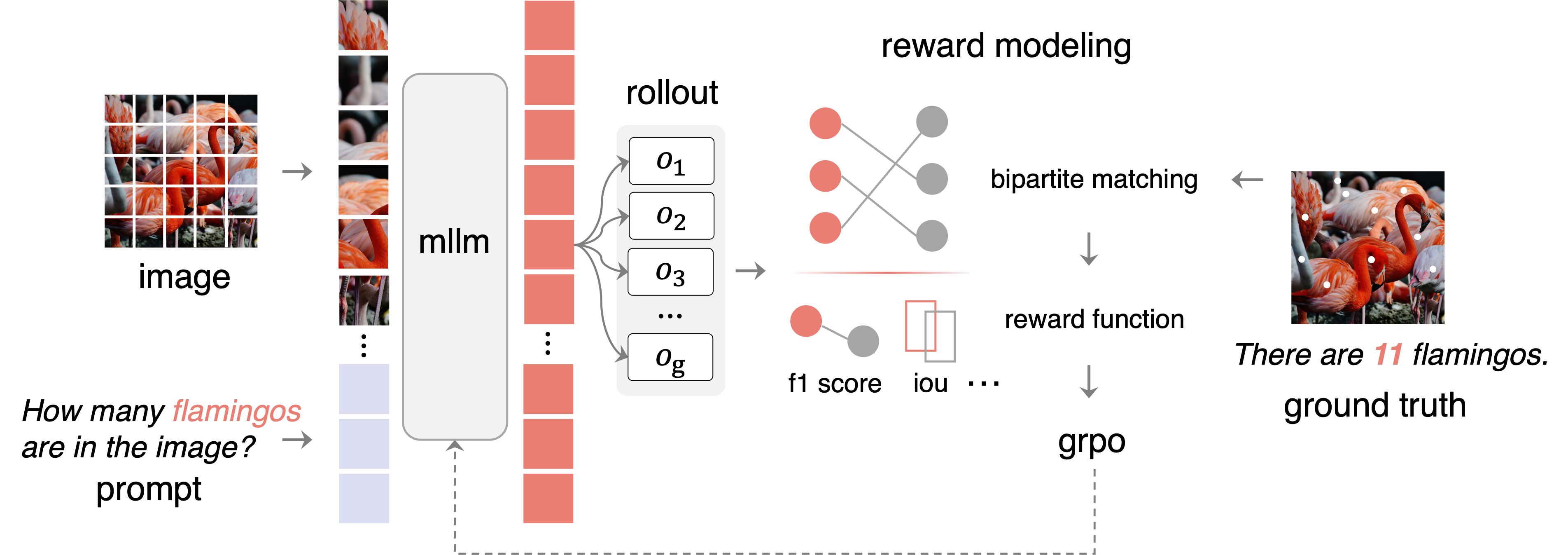
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
En Yu, Kangheng Lin, Liang Zhao, Jisheng Yin, Yana Wei, Yuang Peng, Haoran Wei, Jianjian Sun, Chunrui Han, Zheng Ge, Xiangyu Zhang, Daxin Jiang, Jingyu Wang, Wenbing Tao
- Perception-R1 pioneers the exploration of RL’s potential in MLLM post-training for perception policy learning. We get valuable cognition through experiments. It sets new SoTAs in visual perception tasks, especially object detection. Its novel paradigm enables it to match and surpass expert models, showing the great potential of perception policy learning.
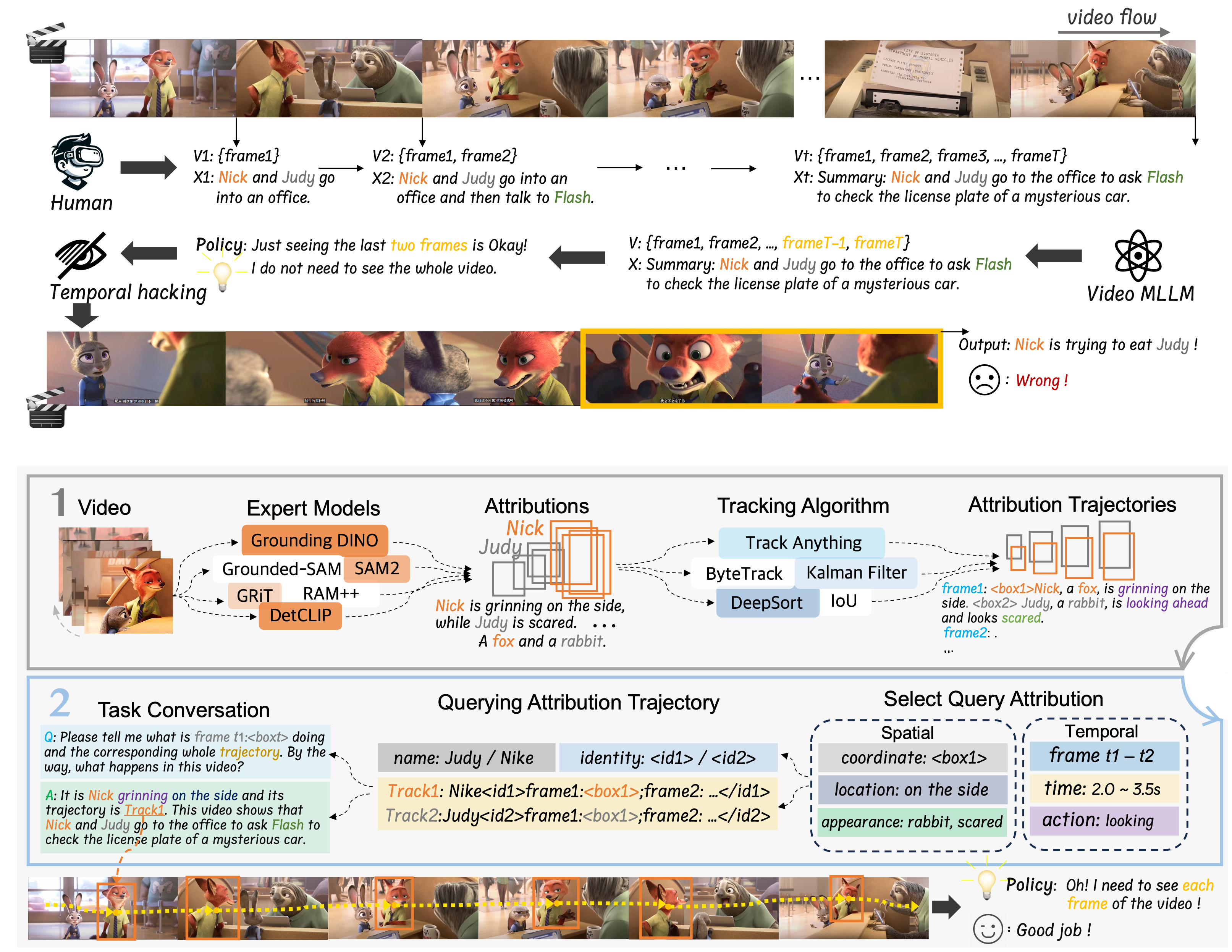
Unhackable Temporal Rewarding for Scalable Video MLLMs
En Yu, Kangheng Lin, Liang Zhao, Yana Wei, Zining Zhu, Haoran Wei, Jianjian Sun, Zheng Ge, Xiangyu Zhang, Jingyu Wang, Wenbing Tao
- This work investigates the shortcut learning in video multimodal large language models and systemally establish temporal hacking theory including: (1) Systematic exploration of the video MLLM unscaling phenomenon, establishing temporal hacking theory from a novel RL perspective. (2) Design of Temporal Perplexity (TPL) score, providing a reliable reference metric for mitigating temporal hacking. (3) Proposing two principles to guide the design of proxy rewards for video-language modeling and further propose Unhackable Temporal Rewarding (UTR).

OVTR: End-to-End Open-Vocabulary Multiple Object Tracking with Transformer
Jinyang Li, En Yu, Sijia Chen, Wenbing Tao
- OVTR serves as the first fully end-to-end open-vocabulary multiple-object tracking framework.

Merlin: Empowering Multimodal LLMs with Foresight Minds
En Yu, Liang Zhao, Yana Wei, Jinrong Yang, Dongming Wu, Lingyu Kong, Haoran Wei, Tiancai Wang, Zheng Ge, Xiangyu Zhang, Wenbing Tao
- Merlin is a groundbreaking model capable of generating natural language responses that are intricately linked with object trajectories. Merlin excels in predicting and reasoning about future events based on initial observations, showcasing an unprecedented capability in future prediction and reasoning.
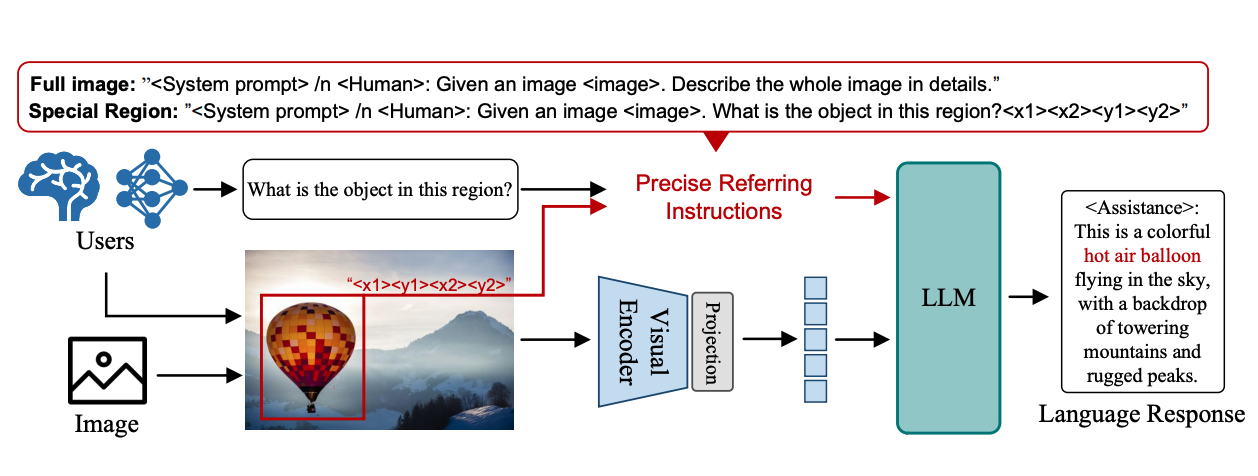
ChatSpot: Bootstrapping Multimodal LLMs via Precise Referring Instruction Tuning
Liang Zhao*, En Yu*, Zheng Ge, Jinrong Yang, Haoran Wei, Hongyu Zhou, Jianjian Sun, Yuang Peng, Runpei Dong, Chunrui Han, Xiangyu Zhang
- ChatSpot is a a unified end-toend multimodal large language model that supports diverse forms of interactivity including mouse clicks, drag-and-drop, and drawing boxes, which provides a more flexible and seamless interactive experience.
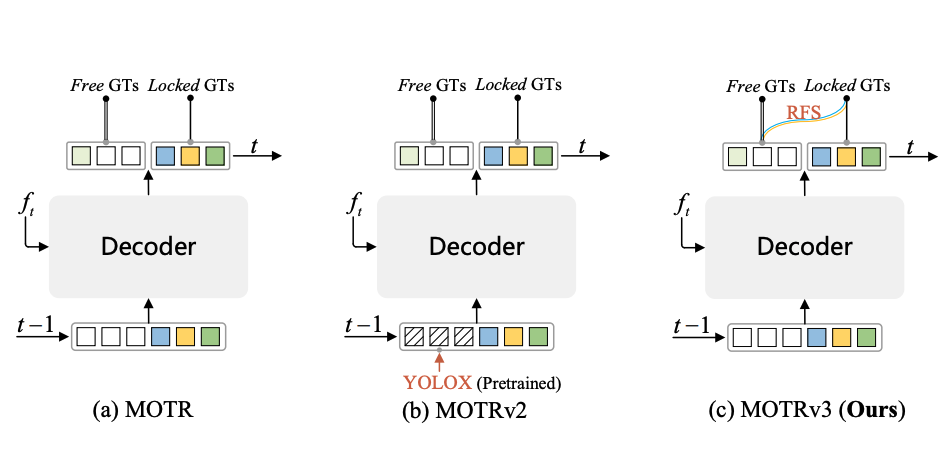
MOTRv3: Release-Fetch Supervision for End-to-End Multi-Object Tracking
En Yu, Tiancai Wang, Zhuoling Li, Yuang Zhang, Xiangyu Zhang, Wenbing Tao
- MOTRv3 is a fully end-to-end multiple object tracking (MOT) model that outperforms existing SOTA tracking-by-detection methods without any assistance of an extra detection network or post-processing.
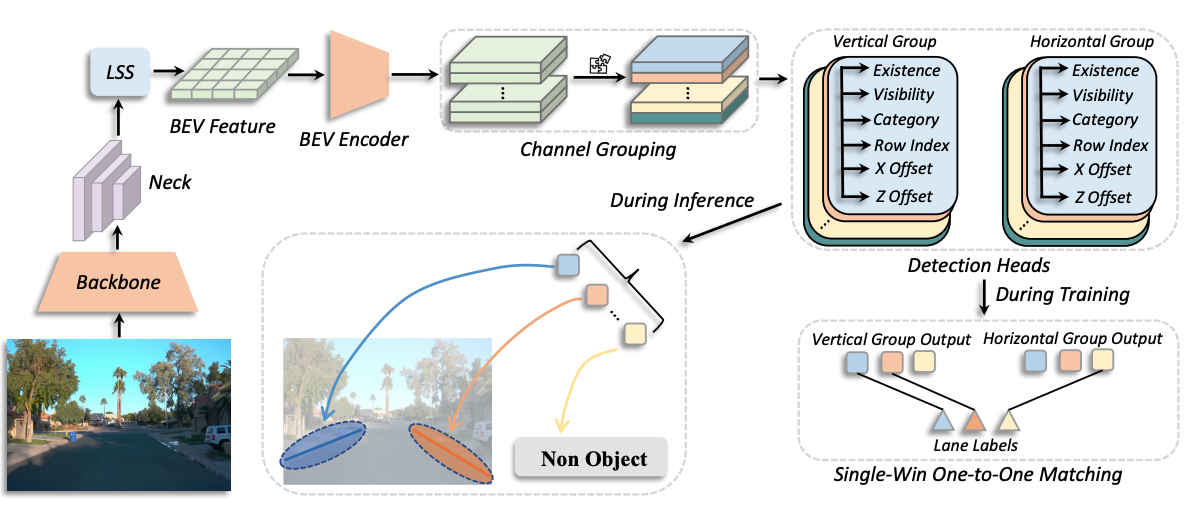
GroupLane: End-to-End 3D Lane Detection with Channel-wise Grouping
Zhuoling Li, Chunrui Han, Zheng Ge, Jinrong Yang, En Yu, Haoqian Wang, Hengshuang Zhao, Xiangyu Zhang
- GroupLane is the first fully-convoluition end-to-end 3D lane detection network. GroupLane achieves SOTA performance on existing mainstream lane detection benchmark, i.e., OpenLane, Once-3DLanes, and OpenLane-Huawei while also ensuring fast inference speed (7 x faster than PersFormer).
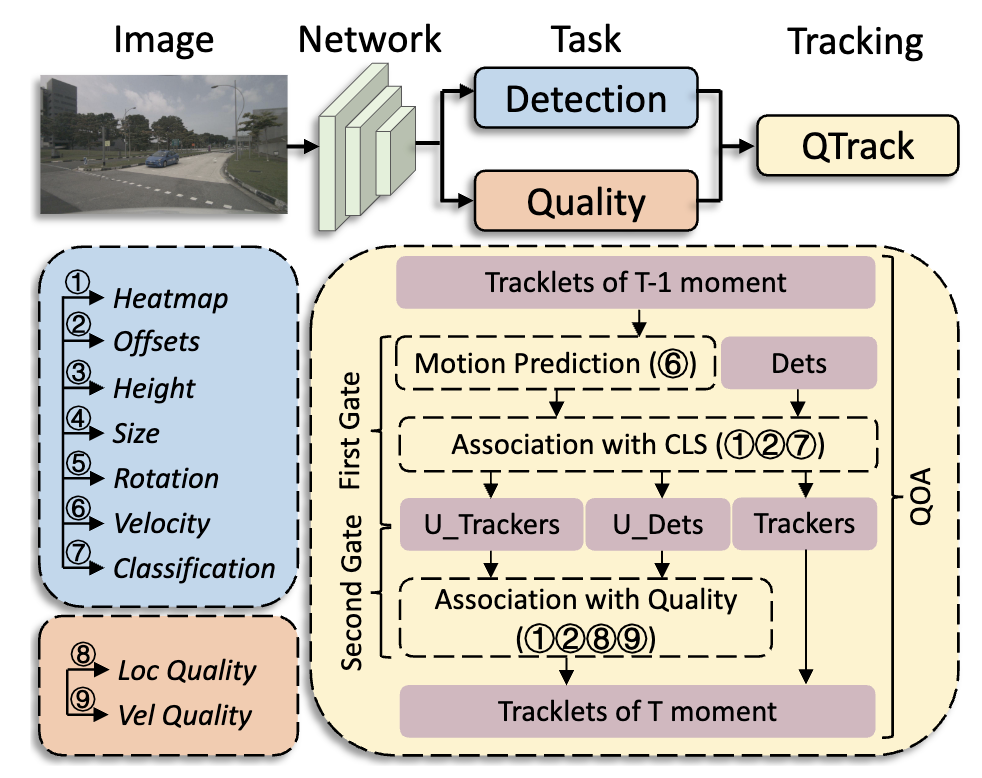
Quality Matters: Embracing Quality Clues for Robust 3D Multi-Object Tracking
Jinrong Yang*, En Yu*, Zeming Li, Xiaoping Li, Wenbing Tao
- QTrack achieves 51.1%, 54.8% and 56.6% AMOTA tracking performance on the nuScenes test sets with BEVDepth, VideoBEV, and StreamPETR models, respectively, which significantly reduces the performance gap between pure camera and LiDAR-based trackers.
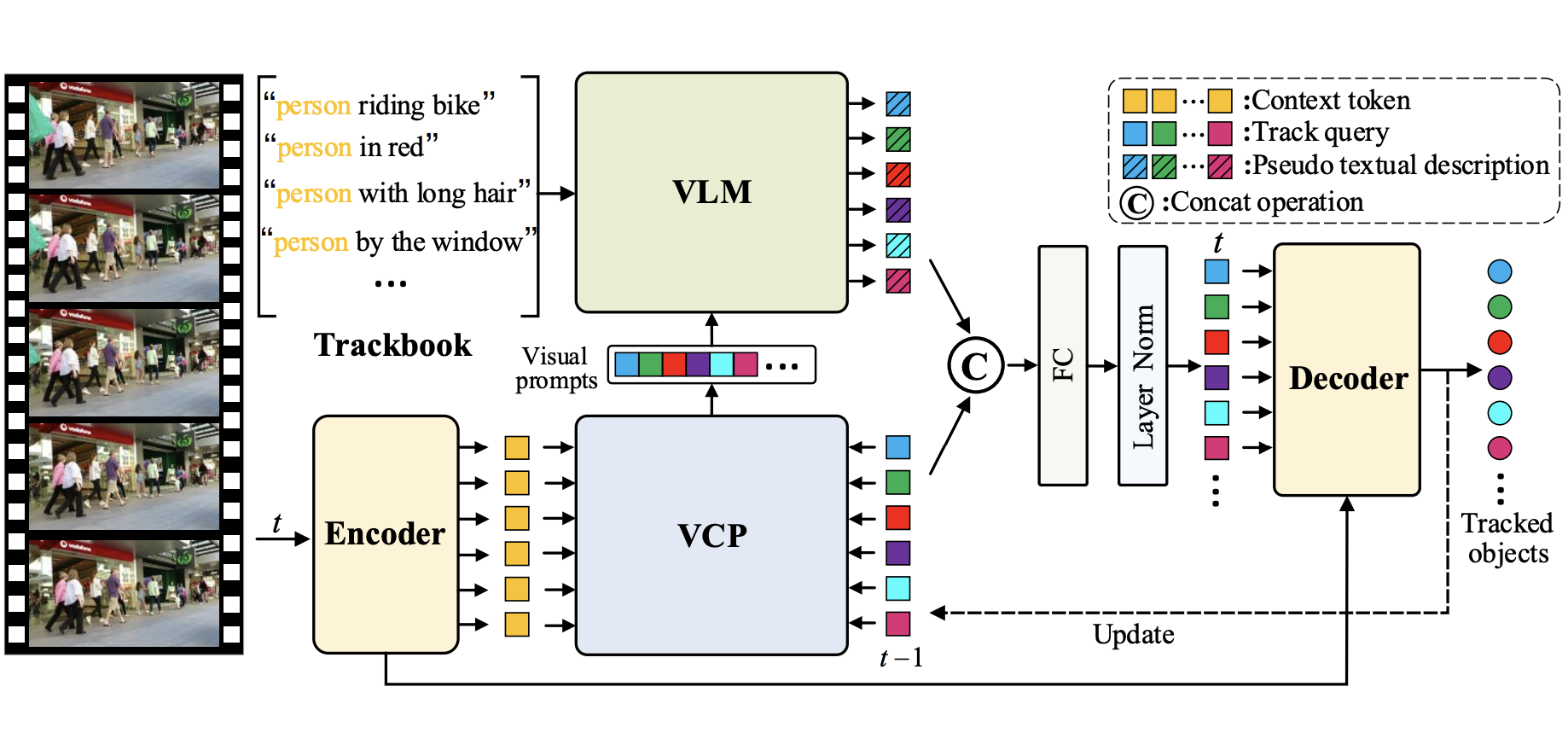
En Yu, Songtao Liu, Zhuoling Li, Jinrong Yang, Zeming Li, Shoudong Han, Wenbing Tao
- We introudce LTrack, the first multiple-object tracking model supporting vision-language modality inputs. Thanks to the dimain invariant of natural language representation, LTrack achieves SOTA performance on our established cross-domain MOT benchmark.
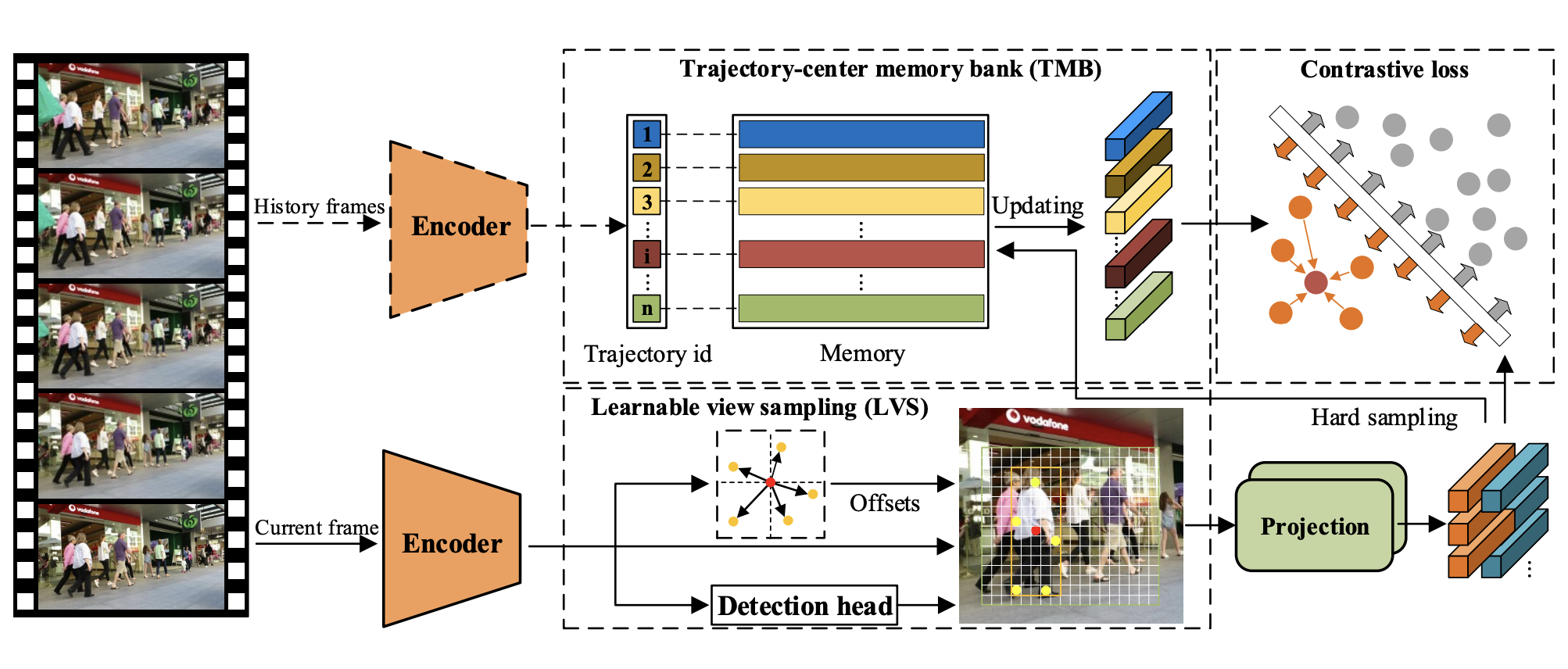
En Yu, Zhuoling Li, Shoudong Han
- We propose MTrack that adopts multi-view trajectory contrastive learning, in which each trajectory is represented as a center vector. By maintaining all the vectors in a dynamically updated memory bank, a trajectory-level contrastive loss is devised to explore the inter-frame information in the whole trajectories. MTrack surpassed preceding trackers and established new SOTA performance.
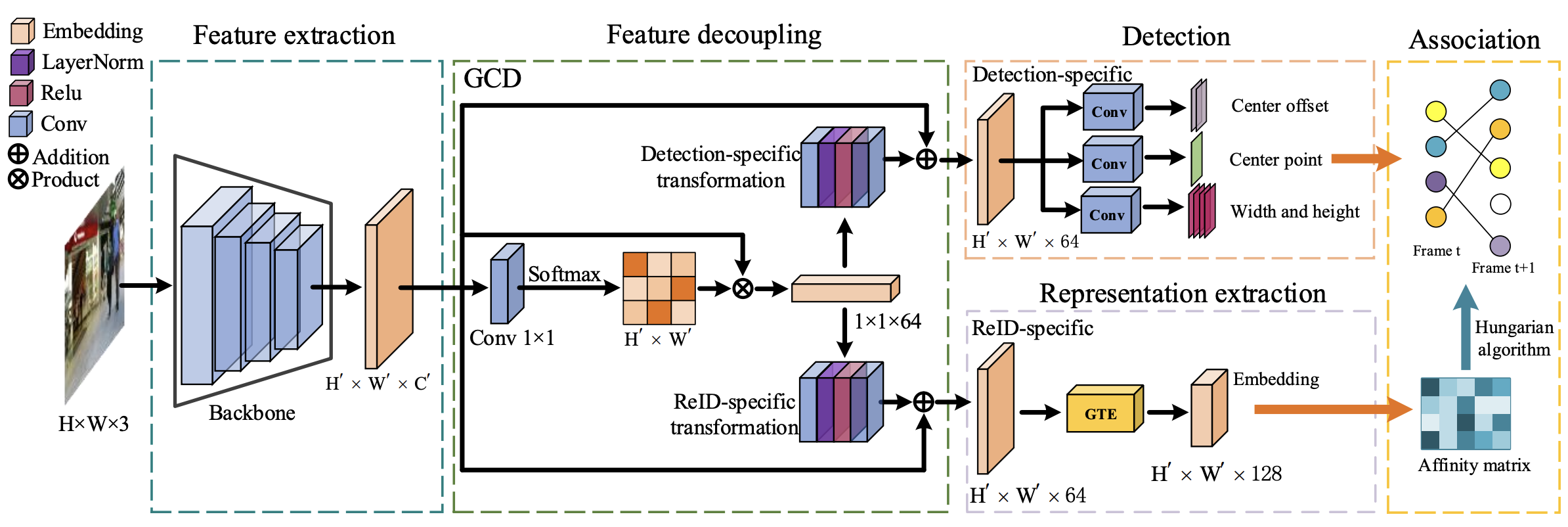
Relationtrack: Relation-aware multiple object tracking with decoupled representation
En Yu, Zhuoling Li, Shoudong Han, Hongwei Wang
-
Perception in Reflection, Yana Wei, Liang Zhao, Kangheng Lin, En Yu, Yuang Peng, Runpei Dong, Jianjian Sun, Haoran Wei, Zheng Ge, Xiangyu Zhang, Vishal M Patel, ICML2025 Poster
-
Rulearena: A benchmark for rule-guided reasoning with llms in real-world scenarios, Ruiwen Zhou, Wenyue Hua, Liangming Pan, Sitao Cheng, Xiaobao Wu, En Yu, William Yang Wang, ICLR2025 Workshop
-
Cross-View Referring Multi-Object Tracking, Sijia Chen, En Yu, Wenbing Tao, AAAI2024 Poster
-
Delving into the Trajectory Long-tail Distribution for Muti-object Tracking, Sijia Chen, En Yu, Jinyang Li, Wenbing Tao, CVPR2024 Poster
-
MAT: Motion-aware Multi-Object Tracking, Shoudong Han, Piao Huang, Hongwei Wang, En Yu, Donghaisheng Liu, Xiaofeng Pan, Neurocomputing
-
Implicit and Efficient Point Cloud Completion for 3D Single Object Tracking, Pan Wang, Liangliang Ren, Shengkai Wu, Jinrong Yang, En Yu, Hangcheng Yu, Xiaoping Li, IEEE Robotics and Automation Letters
-
Efficient few-shot classification via contrastive pre-training on web data, Zhuoling Li, Haohan Wang, Tymosteusz Swistek, En Yu, Haoqian Wang, IEEE Transactions on Artificial Intelligence
🎖 Honors and Awards
- 2025.11 National Scholarship for Doctoral Students.
- 2022.05 Second Prize in the First Global Artificial Intelligence Technology Innovation Competition.
- 2019.08 First Prize in the 13th National College Students’ Intelligent Car Competition.
- 2018.08 National Champion in the 14th National College Students’ Intelligent Car Competition.
📖 Educations
- 2024.07 - 2025.07, University of California, Santa Barbara (UCSB), USA.
- 2022.06 - 2026.06 (excepted), Huazhong University of Science and Technology, Wuhan, China.
- 2020.09 - 2022.06, Huazhong University of Science and Technology, Whhan, China.
- 2016.09 - 2020.06, Huazhong University of Science and Technology, Wuhan, China.
💻 Internships
- 2022.03 - 2024.03, MEGVII Research, Foundation Model Group.
- 2024.03 - 2026.01 (now), StepFun, Multimodal Intelligence Team.